Добрый день!
Подскажите, существуют ли какие либо ограничения для DMN таблиц по размеру, влияет ли размер DMN таблиц на производительность ?
Возможно ли получить выбранную строку решения в таблице через API ?
Добрый день!
Ограничений по размеру нет. Но размер таблицы (число правил в ней) влияет на производительность и на удобство ее сопровождения.
Больше правил - работает медленнее.
Повысить производительность можно отключив историю ( HISTORY_LEVEL_NONE)).
Раньше также встречался такой трюк - не разворачивать модель в базу, а поднимать вручную DMN engine и загружать ее из файла в память:
public class DmnApp {
public static void main(String[] args) {
// configure and build the DMN engine
DmnEngine dmnEngine = DmnEngineConfiguration.createDefaultDmnEngineConfiguration().buildEngine();
// parse a decision
DmnDecision decision = dmnEngine.parseDecision("orderDecision", inputStream);
Map<String, Object> data = new HashMap<String, Object>();
data.put("status", "gold");
data.put("sum", 354.12d);
// evaluate a decision
DmnDecisionTableResult result = dmnEngine.evaluateDecisionTable(decision, data);
}
}
Также способно увеличить производительность (нет запроса к СУБД на извлечение модели).
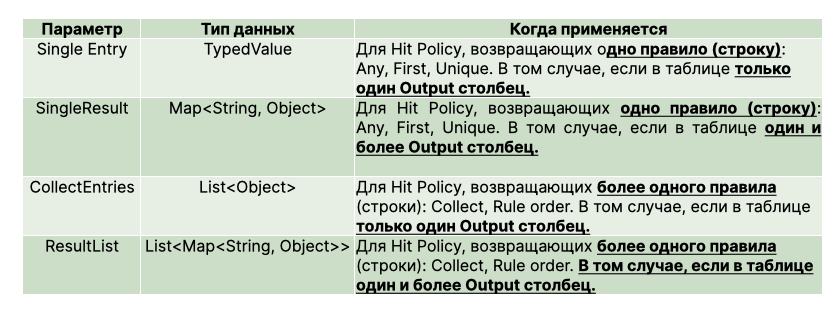
Результат обработки помещается в объект класса DmnDecisionResult, а дальше вы можете с помощью API извлечь нужные данные согласно структуре вашей таблицы:
- .getSingleResult()
- .getResultList()
- .collectEntries()
- .getSingleEntry()
DmnDecisionResult result = decisionService.evaluateDecisionByKey("proposal")
.variables(variables)
.evaluate();
Assert.assertNotEquals(result.getSingleEntry(),then)
Если интересно по производительности, есть относительно свежий бенчмарк:
Параметры таблицы: 16+ тыс правил, 7 входных параметра, 3 выходных.
Camunda, конечно, в сравнении с Drools проигрывает (235 ms vs 0.059 ms). ![]()
Думаю, если потюнить JVM, можно добиться бОльшей производительности.